Whoa! So I was poking around Solana analytics and somethin’ felt off. My instinct said the dashboards were showing the whole truth, but first impressions can be deceiving. Initially I thought it was just noisy volume and flashy UIs, but then I realized the way explorers index and surface data actually reshapes what users trust, and that feeds back into on-chain behavior in ways that are both subtle and powerful. Seriously? Yes—this is about the invisible plumbing that turns raw transactions into narratives people believe.
Hmm… Okay, so check this out—what a blockchain explorer shows you is an editorial act. It chooses which logs to highlight, which token metadata to trust, and which contracts to flag; those are design decisions, not neutral facts. On one hand a neat UI helps wallets and traders move fast. On the other hand, it can obscure failed state transitions and ambiguous program logs that matter for auditors and power users, though actually the problem is often deeper: indexing strategies and RPC sampling create blind spots that regular users never see. My gut told me something was missing when I kept finding edge cases that weren’t visible in the main activity feeds.
Wow! I remember the first time I chased a reverted transaction across multiple explorers—what a mess. The details were scattered between raw log dumps, base64 data, and human-readable parsing that sometimes contradicted itself. Initially I thought the discrepancy was due to timing differences, but after comparing block-level receipts, program logs, and token registry entries I realized that naming conventions and delayed metadata updates create a continuity problem for analysts. I’m biased, but that part bugs me because trust should be about reproducibility, and when explorers diverge it’s a red flag.
Really? Yes, and here’s why it matters for you. If you’re building a dashboard, a strategy, or doing compliance work, those divergences can lead to wrong conclusions that cost money or reputation. For example, misattributed SPL token mints or stale metadata can make a high-value transfer look like a low-value wash, and that confusion propagates to on-chain analytics, tax tools, and marketplaces. There’s also a performance angle—how explorers cache data and how they page large accounts influences what you perceive about network load and resource distribution. I’m not 100% sure on every nuance, but my experience shows these things add up.
Whoa! Diving into Solana explorers means understanding three layers: ingestion, indexing, and presentation. Ingestion is about RPC nodes picking up confirmed blocks and transactions; indexing is about how those items are transformed into searchable records; and presentation is the interface and API that people actually use. Each layer introduces choices and trade-offs—latency versus completeness, normalization versus raw fidelity, and usability versus auditability. Initially I thought speed always wins on Solana, but then I realized that for serious analysis you need both speed and traceability, and that balance is hard to get right.
Hmm… Developers often obsess over throughput and latency, and rightfully so because Solana’s value proposition is speed. Yet here’s the thing. Fast explorers that trim logs aggressively will show you a clean feed but hide the noise that signals failed front-runs, partial fills, or complex program interactions. That’s why when I’m validating on-chain behavior I prefer to cross-reference raw transaction logs with enriched traces that include inner instructions and CPI flows, even if it takes a few extra seconds. Actually, wait—let me rephrase that: I prefer explorers that give me a clear path from high-level events down to raw instructions without losing context along the way.
Wow! Tools matter. Some explorers emphasize UX for beginners and surface token logos, which is great for adoption. Others expose advanced call graphs, inner instruction decoding, and historical state snapshots, which is what researchers and teams need. It reminds me of debugging a distributed system while riding a New York subway—chaotic, fast, and often noisy. My thought process is a bit scattershot here, but trust me, those advanced features change how you interpret events and allocation of resources across validators and programs.
Really? Yes—let me give a concrete example. I once traced a token airdrop that appeared normal on the front page of one explorer, but when I inspected inner instructions I found a custom program that distributed through a chain of CPIs and temporary accounts to obfuscate source balances. The UI-friendly explorer had summarized it as a single «transfer» event and hid the orchestration. On the contrary, an explorer that preserved CPI chains and account-state deltas made the flow obvious within a single session, which saved hours of investigation. This is why I say: not all explorers are created equal for due diligence.
Whoa! If you’re wondering which explorer to trust, here are practical heuristics. Look for clear documentation of how they index data and how often they refresh. Check whether they expose program logs and inner instructions in a readable way. Favor tools that provide block-level transaction receipts and link those receipts to on-chain state snapshots. Ask whether they rely on third-party metadata registries or maintain their own canonical store, because that affects the accuracy of token names and images. I’m not selling anything here—just sharing what I look for when I’m under a deadline.
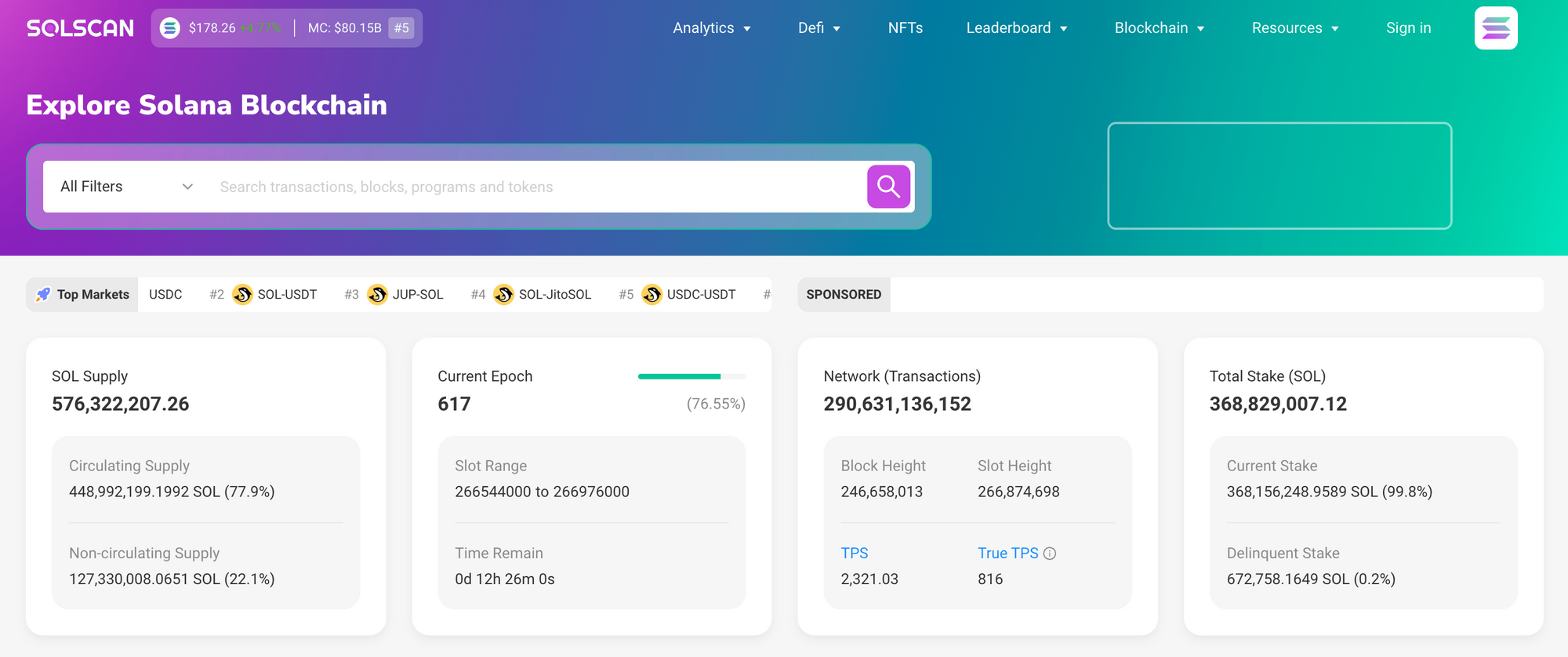
How I use explorers day-to-day and a single go-to link
Whoa! Usually I start with an aggregator to get a quick sense of activity and then drop into a more forensic explorer when something smells off. I’ll be honest: my workflow is messy. I’ll open a wallet trace, then jump to a program log, then check token metadata, and then go back to the raw transaction JSON (very very important to verify). For mainstream sanity checks and quick lookups I use solscan as a starting point because it balances clarity and depth in a way that fits my workflow, though I’m aware it has limits and I’m okay with that. If you want to follow my lead, try solscan and then compare results against an RPC dump for the edge cases.
Wow! Another practical tip: verify unique identifiers instead of names. Token names and logos are mutable and often delayed; the mint address is the invariant you should rely on. When investigating an airdrop or unusual transfer, copy the mint, then scan for all historical mints and burns, and trace how authority keys changed over time. On one hand this feels tedious. On the other hand, doing that work prevents costly mistakes when a token has been rebranded or wrapped multiple times. Also, somethin’ I’ve learned is to use block explorers as one input in a multi-tool audit—don’t let a single UI make the call for you.
Hmm… For teams building on Solana I recommend instrumenting your own lightweight indexer that subscribes to confirmed blocks and retains raw logs for a retention window that suits your forensic needs. That sounds heavy, though actually it’s fairly doable with existing RPC libraries and some storage choices. You can reduce complexity by focusing on program IDs you care about and by snapshotting relevant accounts at a cadence that balances storage cost with investigative usefulness. I’m biased toward pragmatic, not perfect, solutions because time is usually the constraining resource.
Whoa! Let’s talk about things that trip people up. First: metadata race conditions. When an NFT mint updates metadata after initial discovery, marketplaces and explorers may show different states depending on caching and registry refresh strategies. Second: inner instruction opacity. Some explorers decode everything; others only present a subset based on maintainers’ heuristics and that can mislead you. Third: derived account naming—PDAs can look like meaningful accounts, but without context you might misattribute intent. These gotchas are small individually but together they create a lot of analysis friction.
Really? Yes, and the antidote is habitual skepticism paired with systematic validation steps. Start with identifiers, then reconcile logs with state snapshots, and finally confirm human-facing metadata. If you automate this, build retry logic and cross-node verification into your pipelines so you can handle transient RPC discrepancies. On one hand automation reduces manual toil. On the other hand, bad automation replicates mistakes at scale if you don’t design guardrails, so include sanity checks and anomaly alerts.
Whoa! Where is the ecosystem headed? I see more hybrid approaches—explorers that mix user-friendly dashboards with «expert mode» panels that expose raw transactions, CPI graphs, and versioned metadata. I expect better standardization around metadata registries and more transparent indexing specs that make it easier to compare explorers objectively. My instinct says we’ll also get richer program-specific debuggers that can simulate CPI chains locally, though I’m not 100% sure on timelines. Still, the trajectory is toward greater transparency and better tooling for complex diagnostics.
Hmm… Final practical note: when you evaluate an explorer, ask five quick questions—who maintains the index, how are metadata updates handled, do they expose inner instructions, can you access raw JSON receipts, and what’s their refresh latency. Those answers will tell you whether the tool fits your needs for speed, auditability, or both. I’m biased toward tools that let me go deep, which is why I cross-check everything and keep a little checklist for investigations (oh, and by the way… share it with teammates). Somethin’ as simple as a shared habit of verifying mint addresses saves headaches.
FAQ: Quick answers for common explorer questions
Which explorer is best for forensic work?
Wow! For deep dives pick explorers that expose program logs, CPI chains, and raw transaction JSON. Tools that document their indexing strategy and offer block-level receipts are preferable. My instinct said to prefer depth over prettiness, though actually a balance is useful for team workflows.
How do I avoid getting fooled by token metadata?
Really? Rely on the mint address and chain your checks: transaction logs → account snapshots → registry entries. Double-check logos and names only after confirming the mint identity, because metadata can be stale or hijacked.
Is it worth running my own indexer?
Hmm… If you need reproducible audits or customized alerts then yes, it’s worth it. If you just need quick lookups, reputable public explorers plus occasional RPC dumps will do. I’m not 100% sure on cost trade-offs for every team, but start small and iterate.